
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- Miracle morning
- 알고리즘
- importancesampling
- 머신러닝
- neural network
- 선형회귀분석
- 시계열분석
- SF
- Causality
- meta-learner models
- category
- LSTM
- diary
- probabilisticmodeling
- 일기
- Chain rule
- ML
- 비트코인
- Causal Inference
- English
- Montecarlo
- bayes ball algorithm
- UCB
- 암호화폐
- 역전파
- MCMC
- gradient
- linear regression
- neural network for causality
- backpropagation
- Today
- Total
zip-sa | Data is important
Structured Data & Data Preprocessing with PyTorch 본문
인공지능 개발자나 데이터 과학자로서, 데이터를 이해하고 전처리하는 것은 매우 중요한 작업입니다. 특히 정형 데이터는 분석과 모델링 과정에서 자주 다루게 되는데, 이 글에서는 정형 데이터의 주요 유형인 범주형 데이터와 수치형 데이터에 대해 설명하고, 각 유형의 데이터를 전처리하는 방법을 소개하겠습니다.
정형 데이터의 정의
정형 데이터(Structured Data)는 일정한 형식과 구조를 가진 데이터로, 행과 열의 형태로 구성되어 있으며, 데이터베이스나 스프레드시트에 저장됩니다. 이러한 데이터는 쉽게 검색하고 분석할 수 있어 다양한 통계적 분석과 머신러닝 모델에 활용됩니다.
범주형 데이터
범주형 데이터(Categorical Data)는 데이터가 여러 범주로 나뉘어져 있는 형태를 말합니다. 이러한 데이터는 숫자로 나타날 수 있지만, 그 값 자체는 수치적 의미를 가지지 않습니다. 범주형 데이터는 다시 순서형 데이터와 명목형 데이터로 나눌 수 있습니다.
- 순서형 데이터: 범주 간에 순서가 존재하는 데이터입니다. 예를 들어, 교육 수준(고졸, 대졸, 대학원 졸업)은 순서형 데이터에 해당합니다.
- 이미지 예시: 교육 수준을 시각적으로 나타낸 순서형 데이터 그래프 (막대 그래프 등)
- 명목형 데이터: 범주 간에 순서가 없는 데이터입니다. 예를 들어, 혈액형(A, B, AB, O)은 명목형 데이터에 해당합니다.
- 이미지 예시: 혈액형 분포를 나타낸 원형 차트 또는 막대 그래프
이제 범주형 데이터를 어떻게 전처리할 수 있는지 살펴보겠습니다.
범주형 데이터 전처리 방법
범주형 데이터는 모델에 입력하기 전에 적절히 전처리해야 합니다. 일반적으로 사용되는 전처리 방법은 다음과 같습니다:
- 레이블 인코딩(Label Encoding): 각 범주를 숫자로 변환합니다. 예를 들어, 혈액형을 A=0, B=1, AB=2, O=3으로 변환할 수 있습니다.
import torch
import matplotlib.pyplot as plt
# 예시 범주형 데이터 (혈액형)
blood_types = ['A', 'B', 'AB', 'O']
# 레이블 인코딩
label_encoding = {label: idx for idx, label in enumerate(blood_types)}
encoded_labels = [label_encoding[label] for label in blood_types]
# 시각화
plt.figure(figsize=(6, 4))
plt.bar(blood_types, encoded_labels, color='skyblue')
plt.title('Label Encoding of Blood Types')
plt.xlabel('Blood Type')
plt.ylabel('Encoded Value')
plt.show()
- 원-핫 인코딩(One-Hot Encoding): 각 범주를 이진 벡터로 변환합니다. 예를 들어, 혈액형이 A인 경우 [1, 0, 0, 0]으로 표현할 수 있습니다.
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
# 레이블 인코딩된 텐서
encoded_tensor = torch.tensor([0, 1, 2, 3])
# 원-핫 인코딩
one_hot_encoded = F.one_hot(encoded_tensor, num_classes=4)
# 시각화
plt.figure(figsize=(8, 4))
plt.imshow(one_hot_encoded, aspect='auto', cmap='viridis')
plt.title('One-Hot Encoding of Blood Types')
plt.xlabel('Category')
plt.ylabel('Sample Index')
plt.colorbar(label='Value')
plt.show()
수치형 데이터
수치형 데이터(Numerical Data)는 숫자로 표현되며, 이 값 자체가 수치적인 의미를 가집니다. 수치형 데이터는 이산형 데이터와 연속형 데이터로 나눌 수 있습니다.
- 이산형 데이터: 특정 값만 가질 수 있는 데이터로, 주로 정수 형태로 나타납니다. 예를 들어, 제품의 개수(1, 2, 3 등)가 이산형 데이터에 해당합니다.
- 이미지 예시: 제품 개수 분포를 나타낸 막대 그래프
- 연속형 데이터: 연속적인 값을 가질 수 있는 데이터로, 소수점 단위까지 포함될 수 있습니다. 예를 들어, 키나 체중이 연속형 데이터에 해당합니다.
- 이미지 예시: 키나 체중의 분포를 나타낸 히스토그램
수치형 데이터의 전처리 방법도 중요합니다. 이를 통해 데이터를 더 효과적으로 분석하고 모델에 활용할 수 있습니다.
수치형 데이터 전처리 방법
수치형 데이터는 분석과 모델링을 위해 다음과 같은 전처리 과정을 거칠 수 있습니다:
- 정규화(Normalization): 데이터의 범위를 0과 1 사이로 조정합니다. 예를 들어, 키 데이터를 정규화하면 모든 값이 0과 1 사이에 위치하게 됩니다.
import torch
import matplotlib.pyplot as plt
# 예시 수치형 데이터 (키)
heights = torch.tensor([150.0, 160.0, 170.0, 180.0])
# 정규화: (x - min) / (max - min)
normalized_heights = (heights - heights.min()) / (heights.max() - heights.min())
# 시각화
plt.figure(figsize=(6, 4))
plt.plot(heights.numpy(), normalized_heights.numpy(), 'o-', color='green')
plt.title('Normalization of Heights')
plt.xlabel('Original Height')
plt.ylabel('Normalized Height')
plt.show()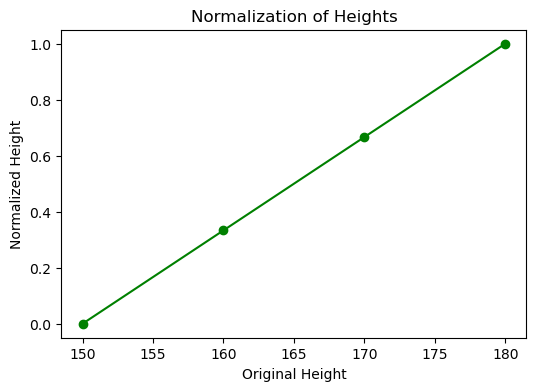
- 표준화(Standardization): 데이터의 평균을 0, 표준편차를 1로 조정합니다. 이는 데이터가 서로 다른 단위를 가질 때 특히 유용합니다.
import torch
import matplotlib.pyplot as plt
# 예시 수치형 데이터 (키)
heights = torch.tensor([150.0, 160.0, 170.0, 180.0])
# 표준화: (x - mean) / std
mean_height = heights.mean()
std_height = heights.std()
standardized_heights = (heights - mean_height) / std_height
# 시각화
plt.figure(figsize=(6, 4))
plt.plot(heights.numpy(), standardized_heights.numpy(), 'o-', color='purple')
plt.title('Standardization of Heights')
plt.xlabel('Original Height')
plt.ylabel('Standardized Height (Z-Score)')
plt.show()
정형 데이터의 유형을 이해하고 이를 적절하게 전처리하는 것은 모델링의 성능을 크게 향상시킬 수 있는 중요한 과정입니다. 범주형 데이터와 수치형 데이터의 특성을 잘 파악하고, 상황에 맞는 전처리 방법을 적용하는 것이 중요합니다. 올바른 전처리는 모델의 정확도를 높일 뿐만 아니라, 데이터의 본질적인 의미를 유지하는 데 필수적입니다.
'Data' 카테고리의 다른 글
| Data for AI Engineer (5) | 2024.08.23 |
|---|
